
Enterprise networkers can be forgiven for thinking that running mission-critical apps across an Internet-based SASE SD-WANs sounds like a recipe for disaster. After all, can an inherently unpredictable network like the public Internet really provide predictable application delivery?
We recently explored that question in a series of tests conducted for one of our clients. We measured latency across various public Internet backbones and Amazon’s private backbone. We compared results against one another, specifically focusing on the contributions of the last and middle miles.
What we found will have a significant impact on how someone designs their first Internet-based SD-WAN. The big lessons: the core of the Internet and predictable application delivery don’t play well together, but Internet access is a different story. Of course, the devil is in the details. To find out more, read on or register for free to receive a copy of the full report.
Testing Purpose and Approach
We wanted to ascertain the source of Internet performance issues and, more specifically, we sought to determine if the erraticness of the Internet stemmed from the Internet core or the last mile. The issue is particularly acute as SD-WAN service providers rely on last-mile Internet access to connect customers to their global networks.
To those ends, we measured the end-to-end delay between workloads in AWS and endpoints on various Internet backbones. We focused on measuring the time to first byte (TTFB), a more accurate metric than a PING, which includes the connection setup times and whose delivery may be delayed by some Internet routers. TTFB only measures the time spent sending a packet and receiving acknowledgment.
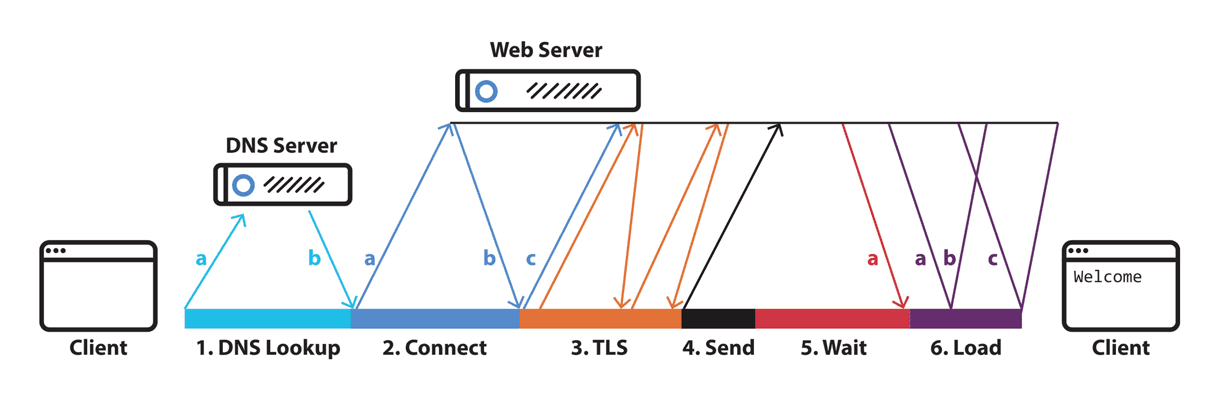
(Source:Catchpoint)
Our testing focused on the time to receive the first byte of the response
Typically, the core strictly means the middle-mile, the network between the local access (last mile) services of the source and destination. In our testing, though, our workloads ran in AWS datacenters that have almost direct access (<10ms) to the Internet backbone. As such, we count the last mile to AWS as part of the core. Were we testing from a corporate network, that might be a different matter.
We used Cedexis to measure the overall site-to-site performance, Catchpoint or Speedtest for last-mile performance, and the difference between the two to calculate the core. We then sanity checked the data by measuring just the core again with Catchpoint. And, finally, we directly measured the core once more, this time for paths between the two AWS instances.
Tests were repeated hundreds of times for each path, and for each path, we reported the median latency and variation (the standard deviation from the median latency). We compared last- and middle-mile performance in terms of their absolute data, relative to overall connection, and, in the case of variation, relative to the latency of that middle- or last-mile segment.
What We Learned
During the testing, end-to-end latency varied significantly primarily due to the fluctuations in the core. The last mile was less stable than the core, deviating from median latency by as much as 196% (versus 143% for the middle mile). The overall impact, though, was negligible as last mile latency constitutes a minor portion of the connection’s overall latency.

As we noted in our post at Network World, the problems we’re discussing don’t only apply to the global Internet, they also apply to the US. During our testing, for example, we found that the path with the greatest variation (143%) occurred within the US (Virginia to San Francisco), not to an international destination.
Recommendations
It’s pretty clear from our research that you can safely build a robust, enterprise Internet backbone if you treat the last and middle miles separately. Within the last mile, take advantage of the ubiquity and low cost of Internet access services. Address concerns about packet loss and availability by a combination of smart ISP and SD-WAN solution selection.
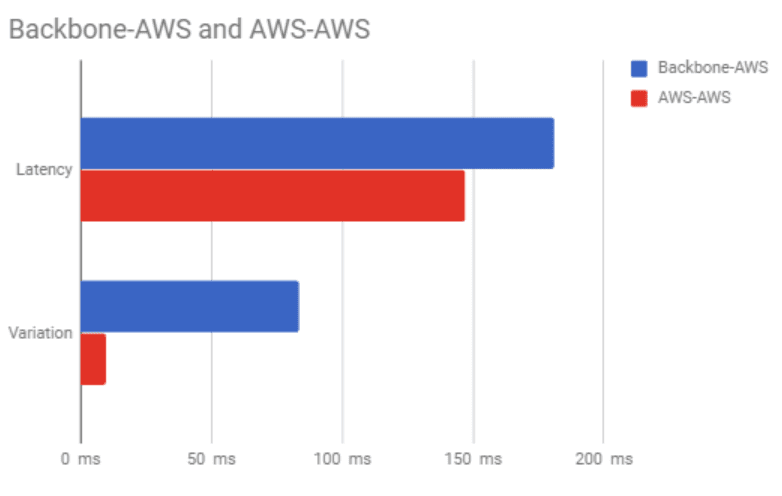
As for the middle-mile, supplement the public Internet on long-distance connections, if predictability is a concern. That’s not to say you have to stick with a carrier service. Using a global private backbone to connect your last miles helps significantly. The proof comes in our AWS testing. We found the median latency between all AWS workloads across Amazon’s network to be nearly 20 percent less than across the Internet and, more importantly, the variation on given paths to be more than 8x better, deviating by no more than 10 ms (versus 84 ms for the public Internet).

For detailed findings and to see the full results, register to receive our full report for free here.
You might also find this article of interest: Latency Across Cloud Backbones Varies Significantly
